Der Enhanced Web Crawler verleiht der HighLevel Conversation AI eine neue Leistungsstufe, indem er interaktive Websites genauso einfach erlernt wie statische Seiten. Durch das automatische Erfassen von bis zu 50 % mehr Seiteninhalten (einschließlich Tabs, Akkordeons und Lazy-Load-Bereichen) kann dein Bot mehr Fragen präziser und zuverlässiger beantworten.
INHALTSVERZEICHNIS
Was ist der Enhanced Web Crawler?
Zentrale Vorteile des Enhanced Web Crawlers
Intelligente Extraktion dynamischer Inhalte
Erweiterte Link-Erkennung
Universelle Website-Unterstützung
So nutzt du den Enhanced Web Crawler
Häufig gestellte Fragen
Verwandte Artikel
Was ist der Enhanced Web Crawler?
Der Enhanced Web Crawler ist die verbesserte Website-Import-Engine innerhalb des Bot-Trainings. Er simuliert echtes Nutzerverhalten, indem er Akkordeons öffnet, Tabs anklickt, scrollt und dynamisch geladene Inhalte sichtbar macht – um jede relevante Information deiner Website zu extrahieren.
Dieses erweiterte Wissen wird anschließend dem Trainingsdatensatz des Bots hinzugefügt – zusätzlich zu den bestehenden Crawl-Optionen Exakte URL, Domain und Pfad.
Zentrale Vorteile des Enhanced Web Crawlers
Tiefere Texterfassung: Extrahiert 30–50 % mehr Seiteninhalte aus modernen SPAs (React, Vue, Angular, Gutenberg usw.)
Erkennt versteckte Inhalte: Liest Akkordeons, Tabs, Modals, Lazy-Load- und Infinite-Scroll-Bereiche
Schnelle Multi-Strategie-Analyse: Führt über 12 Content-Erkennungsstrategien parallel aus
Sichere Interaktionslogik: Vermeidet riskante Aktionen wie Formularübermittlungen, Filteränderungen oder Warenkorb-Klicks
Parallele Extraktion: Reduziert die Crawling-Zeit bei großen und komplexen Websites
Aussagekräftige Crawl-Metriken: Erfasst Zeit, Interaktionen, Inhaltslänge und Speicherverbrauch zur Optimierung
Intelligente Extraktion dynamischer Inhalte
Öffnet automatisch Akkordeons, klickt durch Tabs, aktiviert Lazy-Loading und deckt versteckte Inhalte auf
Mehr als 2 intelligente Erkennungsstrategien (semantische Inhalte, strukturierte Daten, Metadaten) laufen parallel für maximale Geschwindigkeit
Sichere Interaktions-Engine verhindert störende Aktionen wie Formularübermittlungen oder Filteränderungen
Erweiterte Link-Erkennung
Erkennung aus mehreren Quellen: HTML-Parsing, JavaScript-Analyse und interaktionsbasierte Entdeckung
Findet Links, die sich hinter aufklappbaren oder dynamischen Bereichen verbergen
Intelligente Duplikat-Erkennung bei gleichzeitiger Beibehaltung beschreibender Linktexte
Universelle Website-Unterstützung
Funktioniert mit allen Website-Typen: statisches HTML, WordPress, React-SPAs, Vue- und Angular-Anwendungen
Schnellere Crawls durch parallele Inhaltsextraktion
Vollständige Transparenz durch detaillierte Metriken (Verarbeitungszeit, Interaktionen, Inhaltslänge, Speicherverbrauch)
So nutzt du den Enhanced Web Crawler
Schritt 1: Zur Knowledge Base navigieren
Klicke in deinem Sub-Account auf AI Agents
Öffne den Tab Knowledge Base
Erstelle eine neue Knowledge Base oder bearbeite eine bestehende
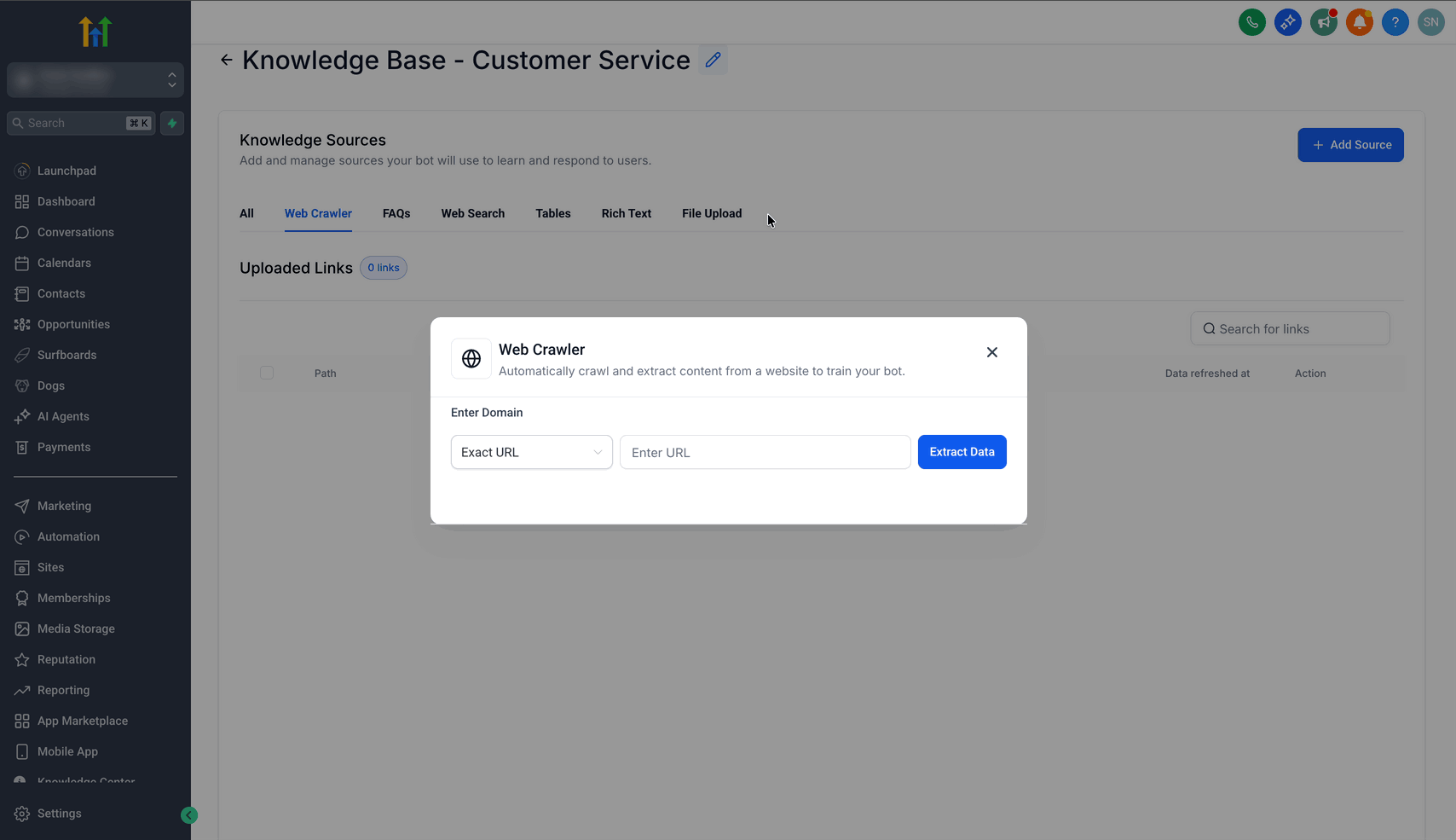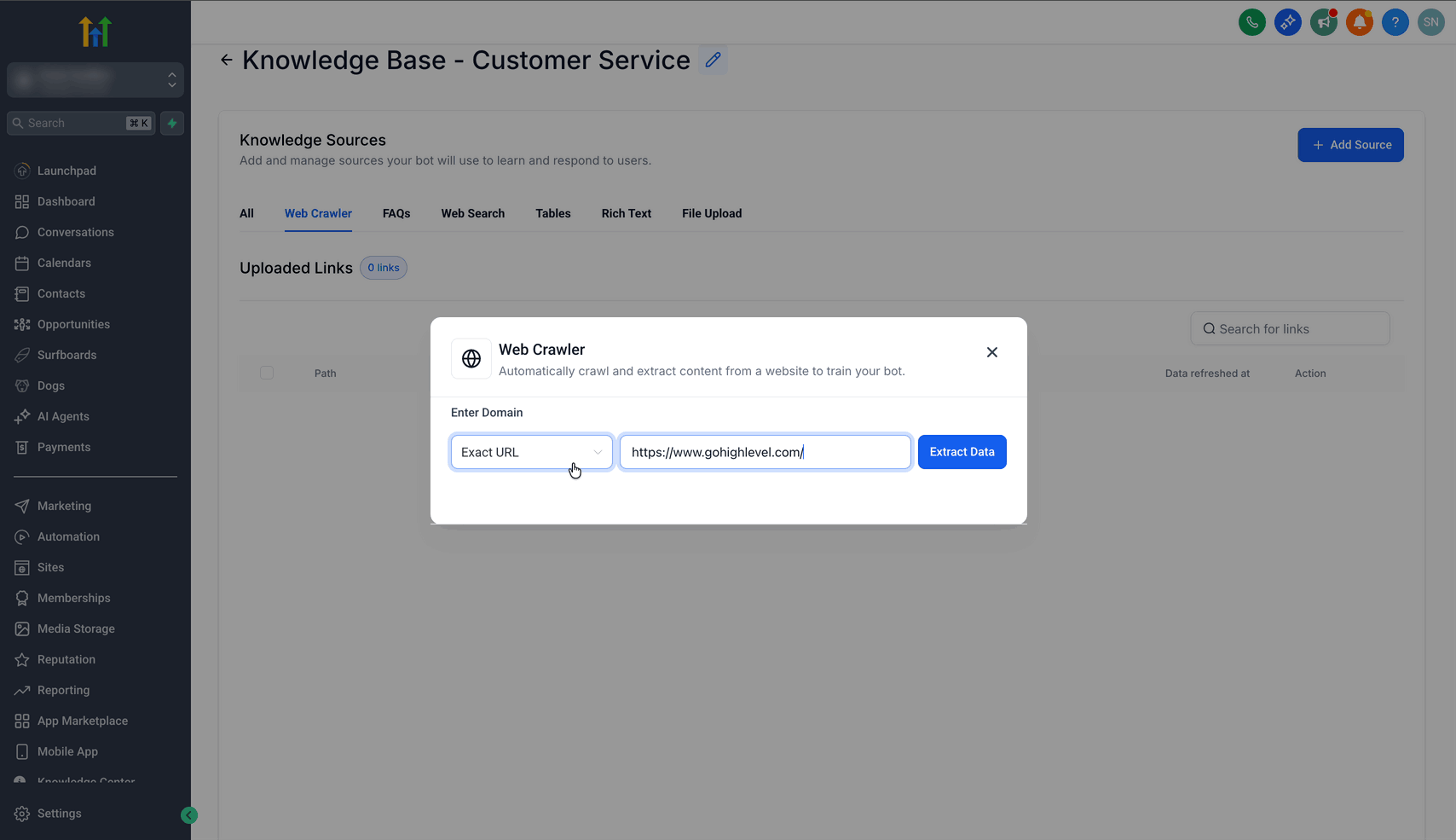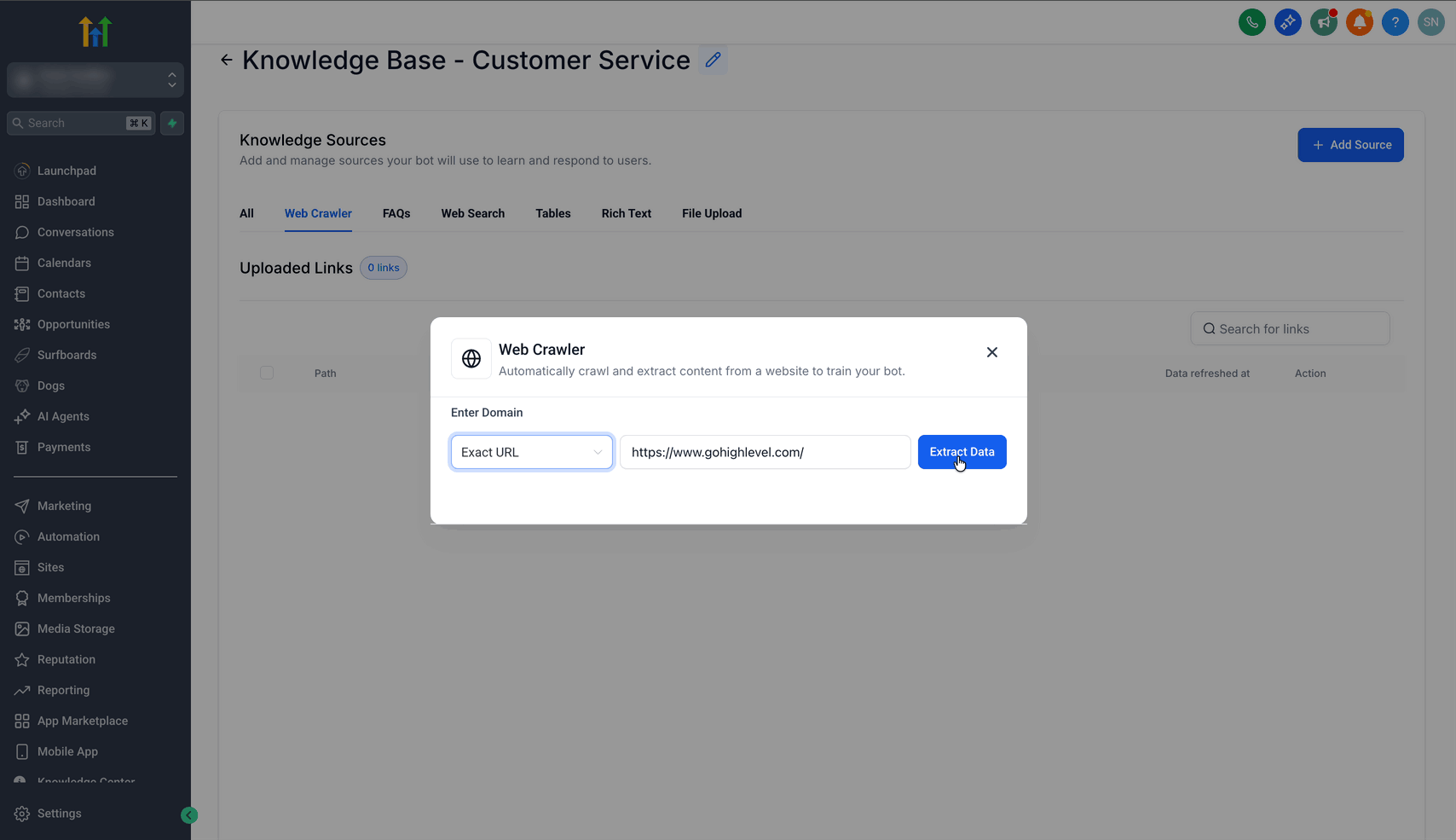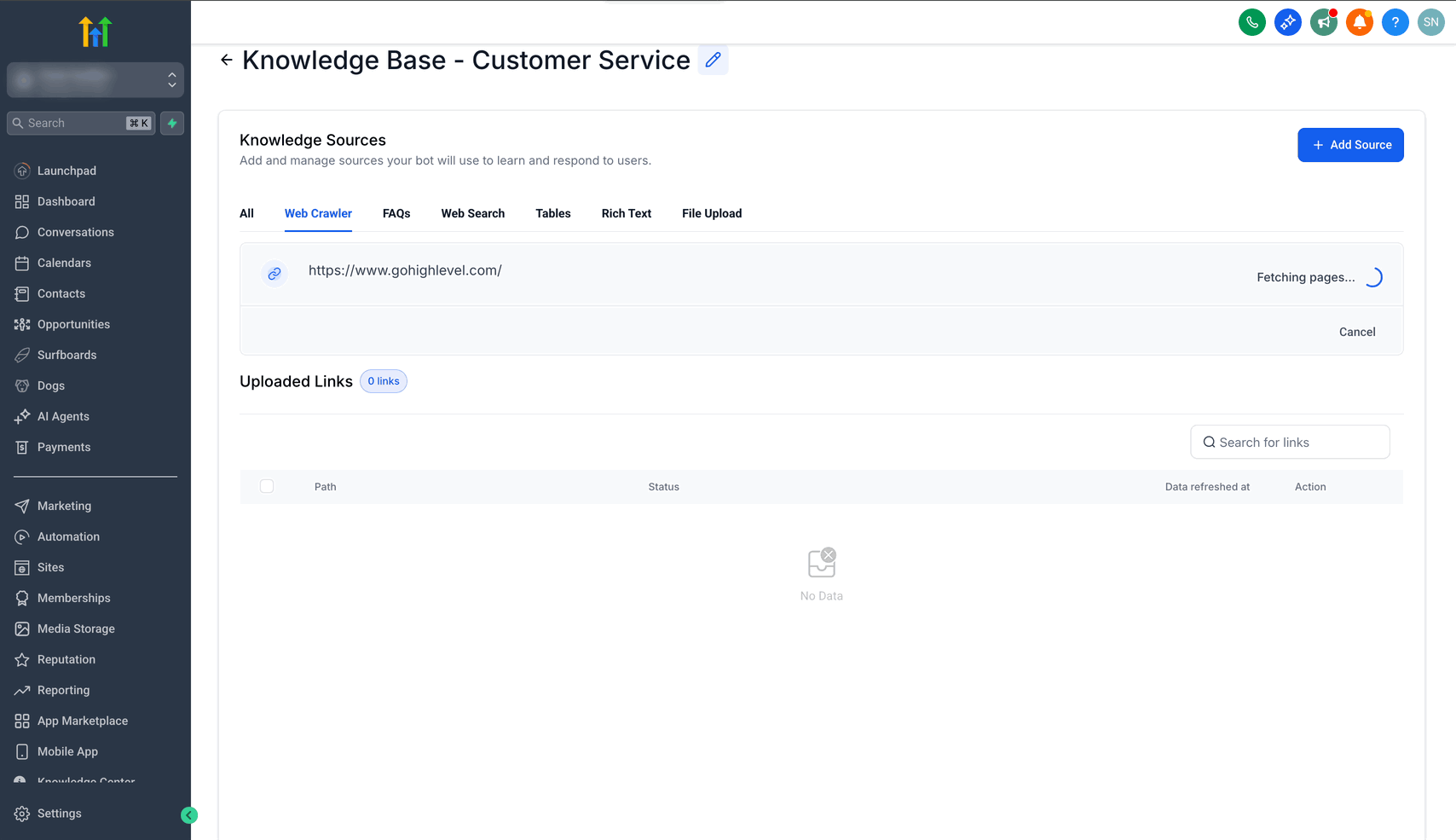
Klicke auf + Add Source
Wähle Web Crawler

Schritt 2: Domain-Typ auswählen und Domain eingeben
Je nach gewähltem Domain-Typ wird festgelegt, wie viele URLs für das Bot-Training gecrawlt werden:
Exakte URL: Crawlt nur eine einzelne Seite
Beispiel:https://www.gohighlevel.com/Alle URLs mit diesem Pfad: Crawlt alle Seiten innerhalb eines Pfads
Beispiel:https://www.gohighlevel.com/marketingAlle URLs dieser Domain: Crawlt alle Seiten einer Domain
Beispiel:https://www.gohighlevel.com/
URL hinzufügen
Auf Extract Data klicken
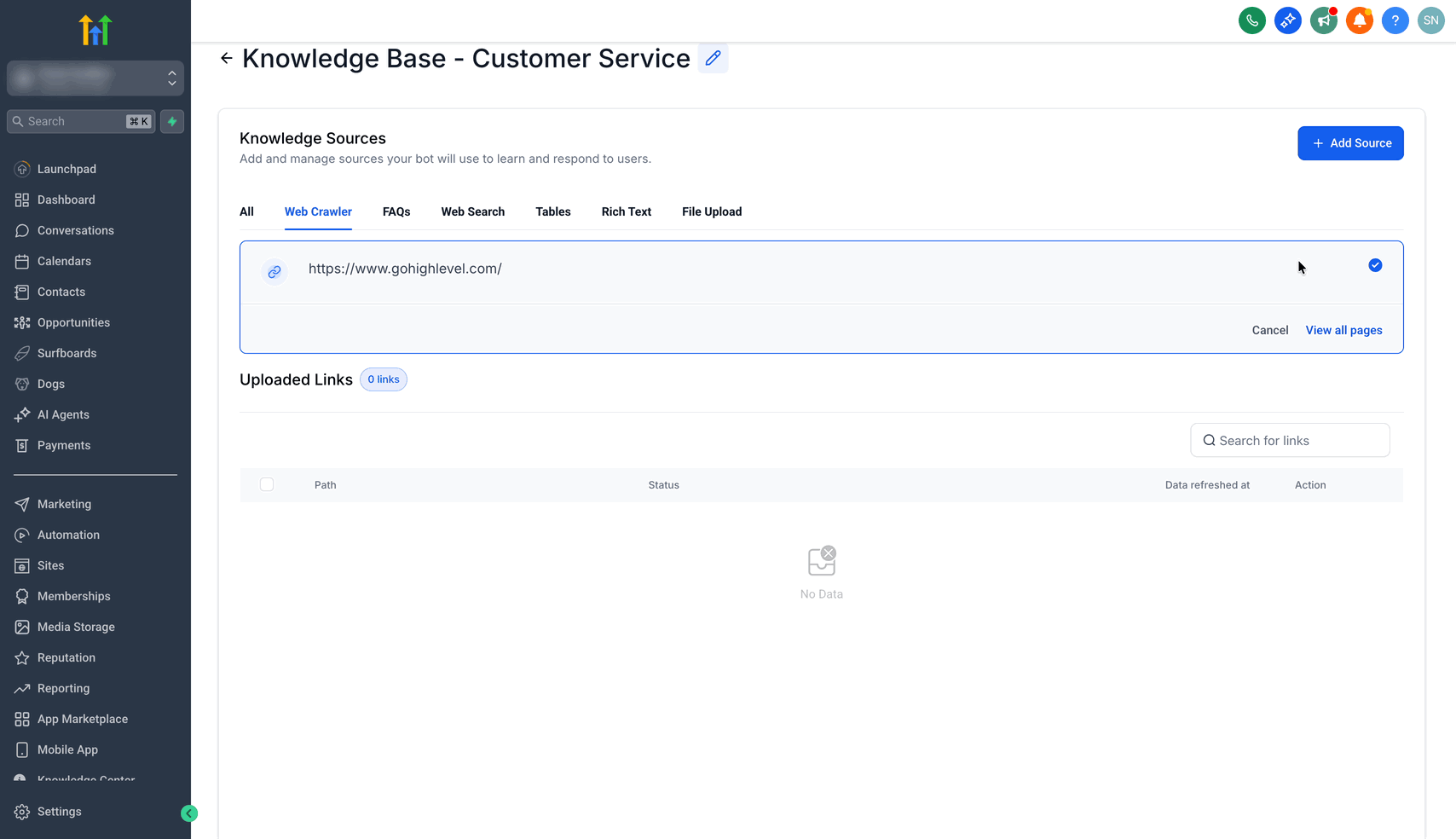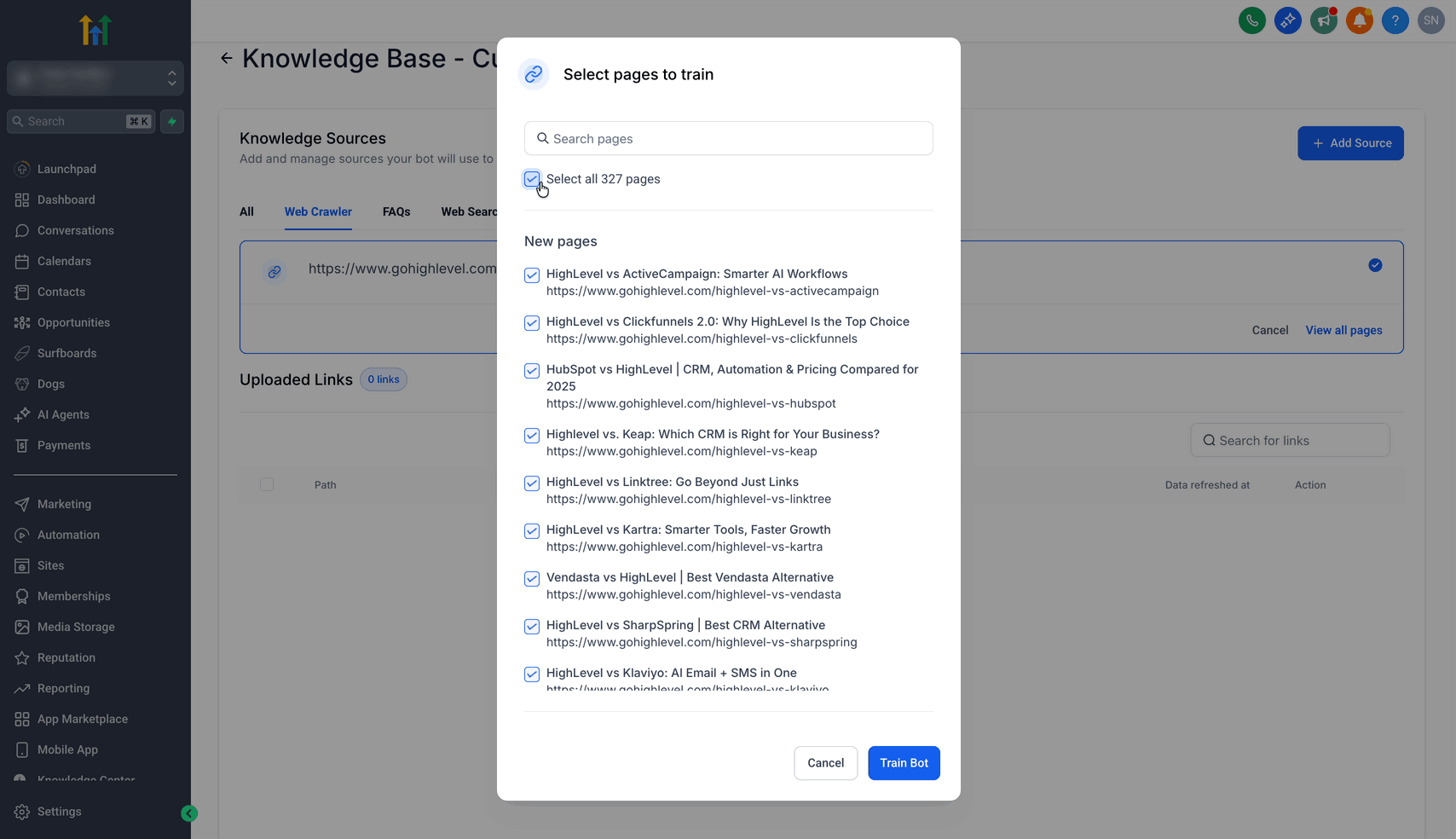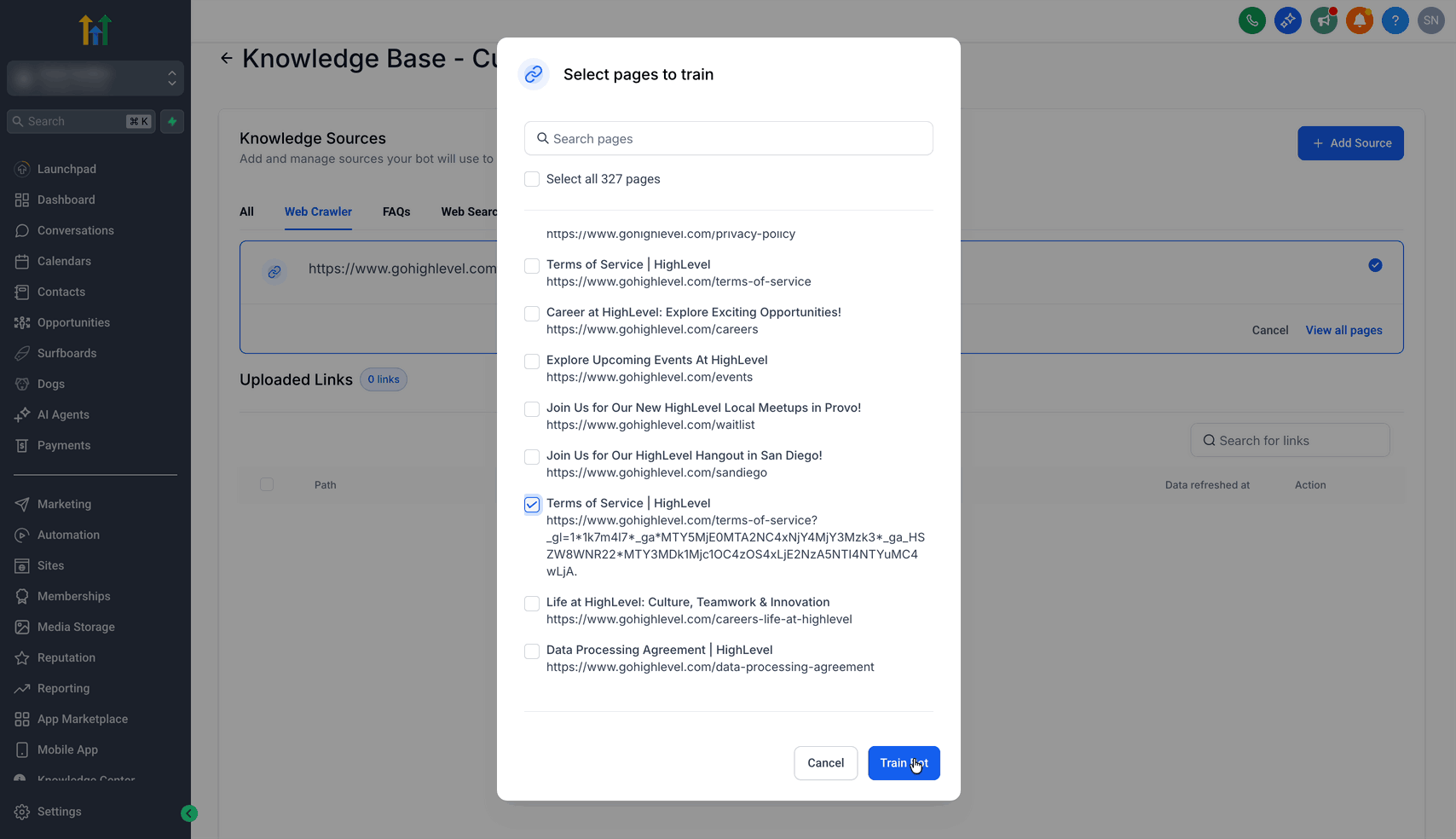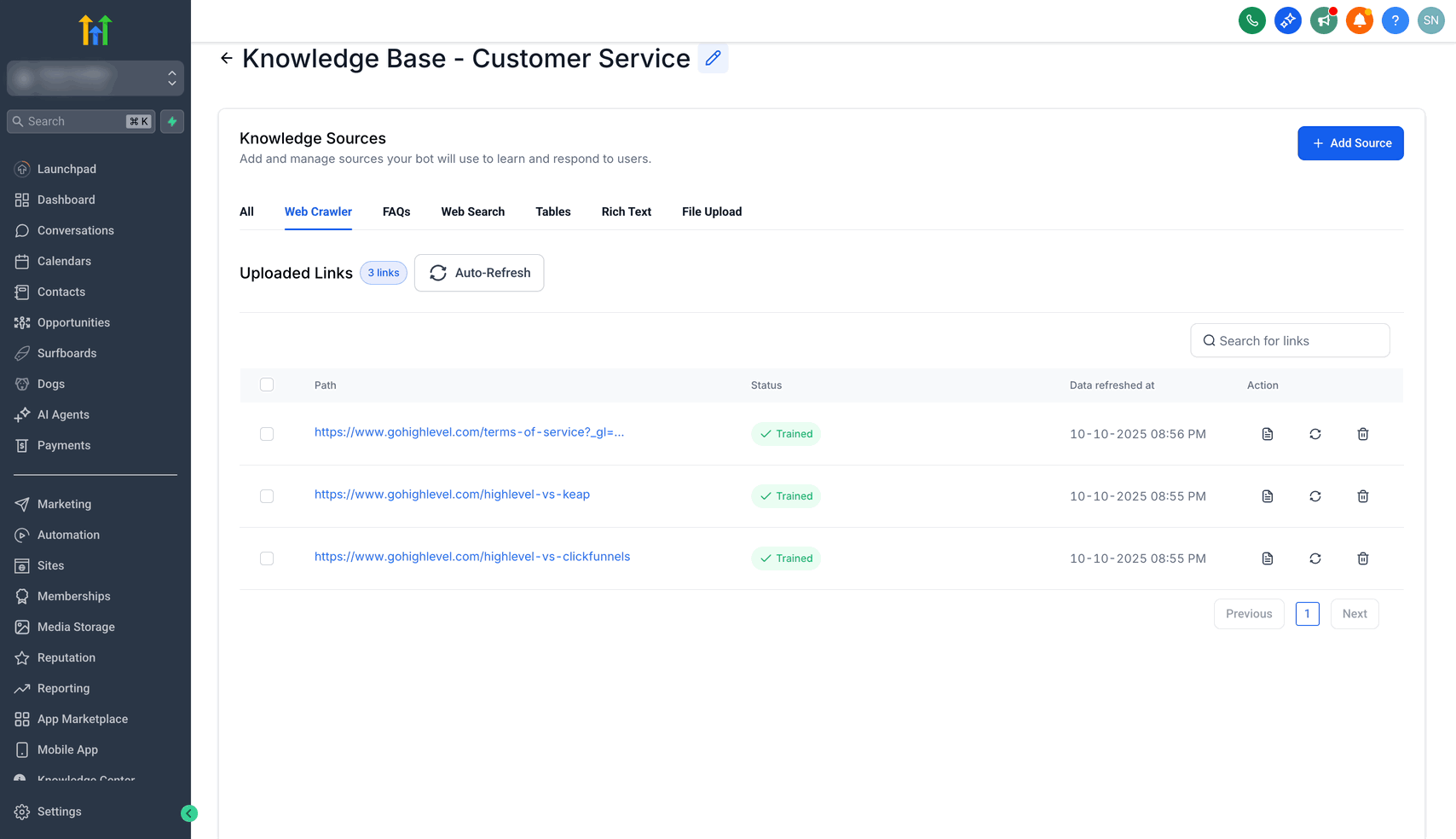
Schritt 3: Gecrawlte URLs auswählen
Nach Abschluss des Crawls auf View All Pages klicken
Alle URLs auswählen oder einzelne Seiten per Checkbox markieren
Auf Train Bot klicken
Häufig gestellte Fragen
F: Was bedeutet „intelligentere Inhaltserkennung“?
Der Crawler erfasst jetzt bis zu 5,2-mal mehr Website-Inhalte, darunter Testimonials, Features, Kontaktdaten und Servicebeschreibungen, die zuvor häufig übersehen wurden.
F: Wie zuverlässig ist das Training mit dem neuen Crawler?
Die Erfolgsquote stieg von 81,6 % auf 94,7 % – über Business-, E-Commerce- und interaktive Websites hinweg.
F: Muss ich etwas konfigurieren, um wichtige Bereiche zu extrahieren?
Nein. Über 6 parallele Erkennungsstrategien identifizieren automatisch Hero-Bereiche, Testimonials, Produktbeschreibungen, Team-Profile, Preislisten und Kontaktdaten.
F: Kann der Crawler interaktive oder versteckte Inhalte lesen?
Ja. Er öffnet Akkordeons, navigiert durch Tabs und macht Lazy-Load-Inhalte sichtbar.
F: Welche strukturierten Daten werden extrahiert – und warum ist das wichtig?
Der Crawler erfasst 94 % mehr strukturierte Daten (Öffnungszeiten, Kontaktdaten, Preise, Services), was der KI ein deutlich besseres Verständnis deines Unternehmens ermöglicht.
F: Klickt der Crawler auf Checkout-Buttons oder sendet Formulare ab?
Nein. Die sichere Interaktions-Engine ignoriert Formulare vollständig.
F: Was passiert bei Login-geschützten Inhalten?
Es werden nur öffentlich zugängliche Inhalte gecrawlt. Inhalte hinter Logins werden nicht erfasst.
Verwandte Artikel
Conversation AI einrichten
Conversation AI Bot – erklärt
Erweiterte Einstellungen – Conversation AI
Conversation AI – Übergabe an menschlichen Agenten